Vibes are not enough: Lessons learned fixing a vibe coded feature
We added a feature where users can see changes between nodes in a draft and a published workflow. The initial implementation was a dev-style diff viewer like GitHub diffs which would show a list of nodes and whether a node has been added, removed, or modified between the draft and published versions. Expanding a node would show how the fields of the node changed too, as seen in the photo below.
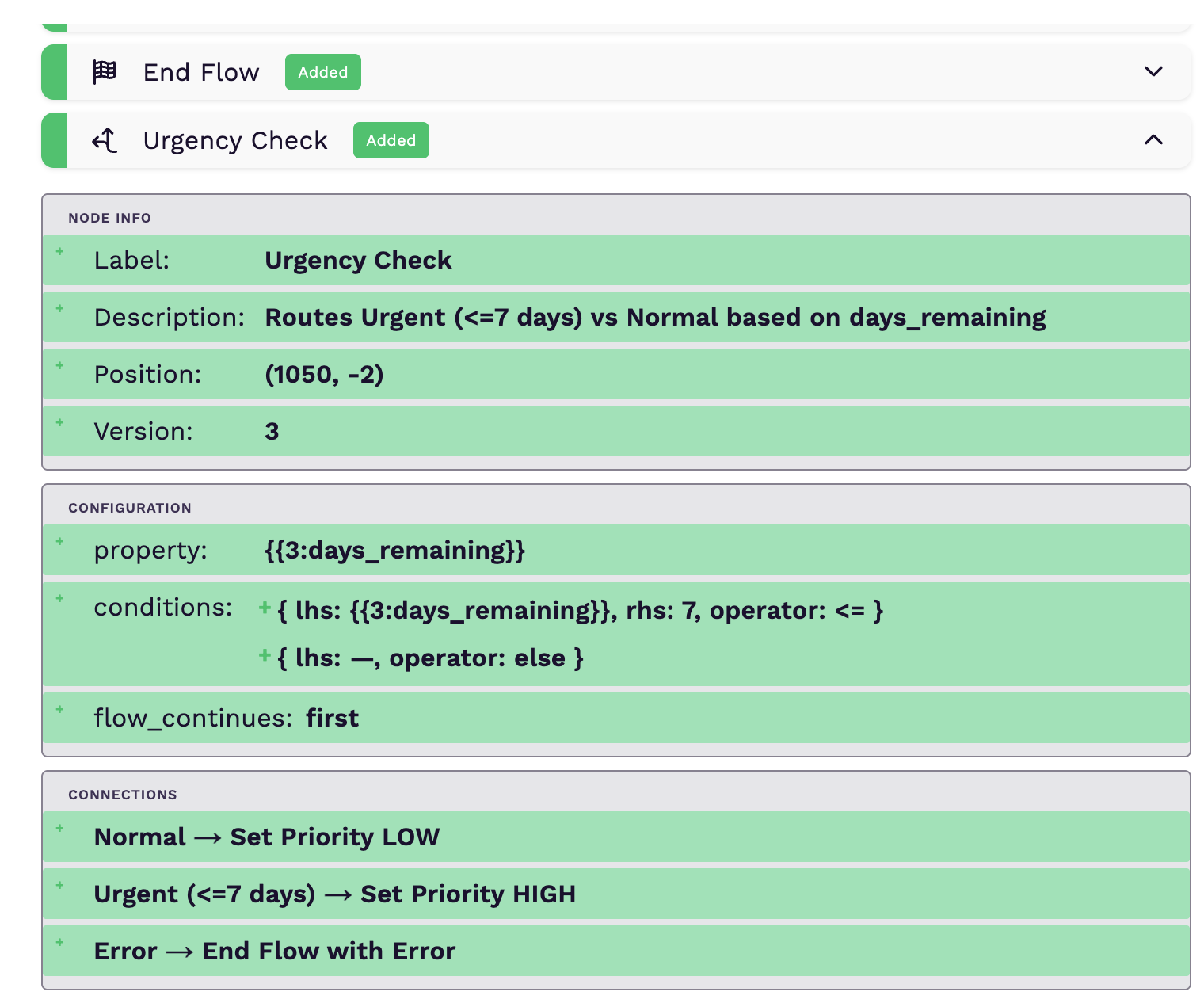
I was tasked with looking into a bug where the diff viewer was comparing different nodes of the same type when showing what changed. I was stumped by how many other cases were failing when I tried to reproduce the issue. Below is a list of some of the failing cases:
- If a published version had more than one node of the same type, the diff viewer could compare different instances of the same node, providing an inaccurate diff.
- When a node was removed in the draft version, all of its fields should appear as removed, but the configuration fields appeared as added.
- There were missing node fields in the diff.
- When a node was added/removed, its label field would appear as modified in the diff viewer.
- Connections would sometimes appear as added or removed even if there were no changes to them.
- Configuration fields on nodes with non-primitive values wouldn't show any change in the diff viewer.
- On a slower connection, the viewer would first show a wrong diff, then show a proper diff after the published workflow information is fetched.
- On the node configuration, there are fields which could have child items (e.g., conditions in the shared screenshot). These would always appear as added whether a node was removed, added, or if a property of any of the items was edited/removed.
With all these issues, the feature almost never gave a correct diff unless you made a minor change. Fixing all the cases revealed some lessons I could share about vibe coding:
1. LLMs are still greedy:
In computer science, a greedy algorithm solves problems by making the best possible choice at each step, aiming for a globally optimal solution. Greedy algorithms are fast and efficient but they do not always guarantee the best possible solution for all problems.
This is similar to how LLMs work: the model predicts the next token by simply picking the one with the highest immediate probability. By always picking the best immediate word, it can miss a sequence that would have been better overall but started with a lower probability token. Even though techniques like chain of thought or simply using a thinking model reduce this, if it's not aware of system constraints that are not in code or how users actually use your feature, it will just choose the first solution that makes sense.
The case that demonstrates this in the list of issues was where the diff viewer could compare different nodes of the same type. When I went through the code to see why this was happening, it was because it was depending on the node type and position to match and diff a node in the draft and published workflows. This is what made sense for it to do, and the engineer who implemented this feature never spotted the flaw. Using a unique identifier between the two workflows—which in our case was a field called node_index on the node data—was the correct way to match nodes.
2. Complex implementations still need a human in the loop:
When adding a new complex feature like a diff viewer to an existing complex codebase, I think it's necessary to understand what a model is going to do and guide it to do it in a way that keeps the codebase maintainable but also reduces cases of regression.
Even though models are good at extracting context from existing code, sometimes they might miss undocumented constraints. For example, when matching nodes, the model couldn't use node IDs in our implementation because workflows are immutable, and the node IDs between the draft and published versions are different. But each node has a unique field called node_index on its data that is the same between the published and draft versions, which is the only way to match and diff the nodes correctly. It missed this detail, and the engineer who wrote the initial version didn't specify it.
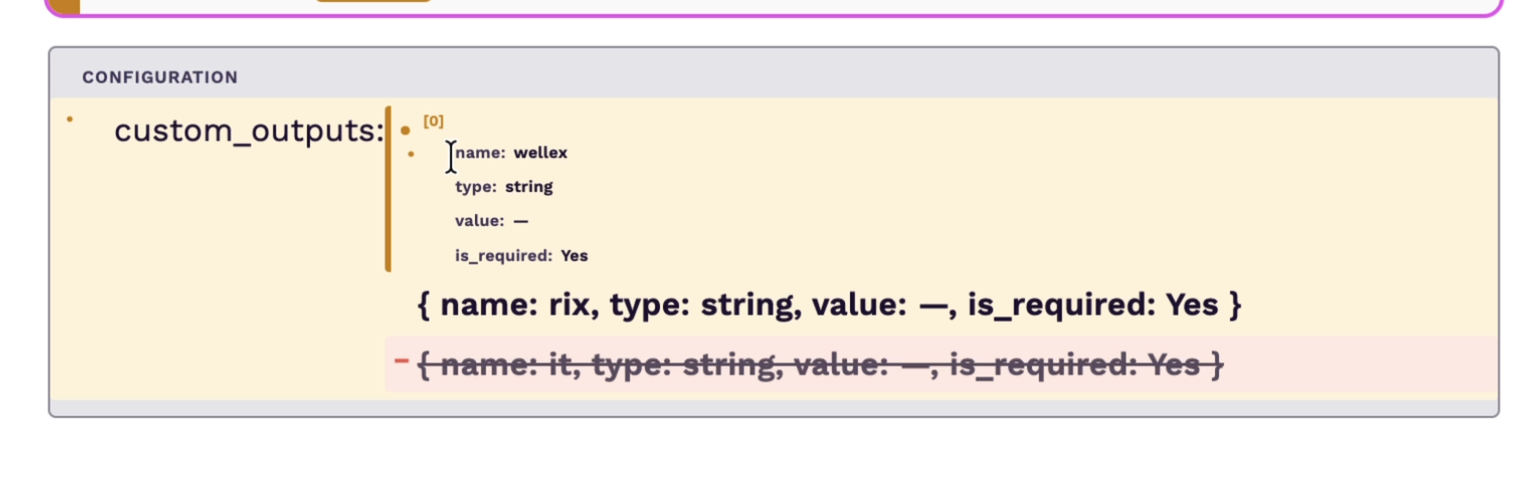
Models don't know the expected user experience unless you specify it. For example, initially, fields on the node configuration that have multiple items used to appear as added regardless of how they were changed, but this is not what the user expected to see. After the fixes, users could see which fields on a particular item changed. Looking at the name of the first item in the screenshot, they could see that the first item was modified, the last item was deleted, and the entire custom_output field was modified. All this was missing initially, and we showed an inaccurate diff to the user.

In summary, you still have to define nuanced system constraints and how users are going to use your feature.
3. AI amplifies your capabilities:
There is a common joke in the AI community that goes like: "I used to have at least 3 unfinished projects; thanks to AI, I now have fifteen." I think it's far from a joke. If you are a finisher, AI tends to amplify that, and if you are a project graveyard owner, it can help you grow your graveyard.
Most non-trivial or detail-oriented features require great attention to detail. If you are a detail-oriented person, chances are that AI is going to amplify how good you are at nailing detail-oriented solutions because you will provide all the necessary details. Models are good at producing detail-oriented solutions really fast if you give them all the correct details. On the other hand, if you pay less attention to detail, models still amplify that; they are also good at implementing solutions that lack detail really fast.
Take getting the diff for fields with multiple values on the node configuration (e.g., custom outputs) as an example. The model matched items between the draft and published node based on their position in the array. This would always give the wrong diffs when items were reordered, when a new item was inserted in the middle or at the beginning of the list, or when an item was removed from the beginning or between items in the list. This was missed by the engineer who did the initial implementation, and the model thought positional matching was okay. Introducing a unique identifier that is the same between the draft and published node for each item ensured that we could match items between the published and the draft nodes correctly and properly diff them.
At the end of the fixes, we had a tool that not only shows the proper state of the node changes between published and draft versions, but also shows the correct changes for all fields on the node.
If you have tips on reducing regression in features implemented with AI or any lessons you would like to share, I'd love to hear them in the comments.
Related Posts (3)
What started as a multiplayer prototype revealed duplicated state, overloaded slices, and blurred team ownership. This is how we refactored it — and why reading the docs still matters when coding with AI.
We needed to solve concurrent editing in our React Flow workflow builder. Here's how Yjs + WebSockets, Yjs + SSE, and Liveblocks compared — and why we chose locks instead.
A tooltip bug where the AI fix “worked” by spreading z-index, but the real fix was keeping portals inside the right stacking context.